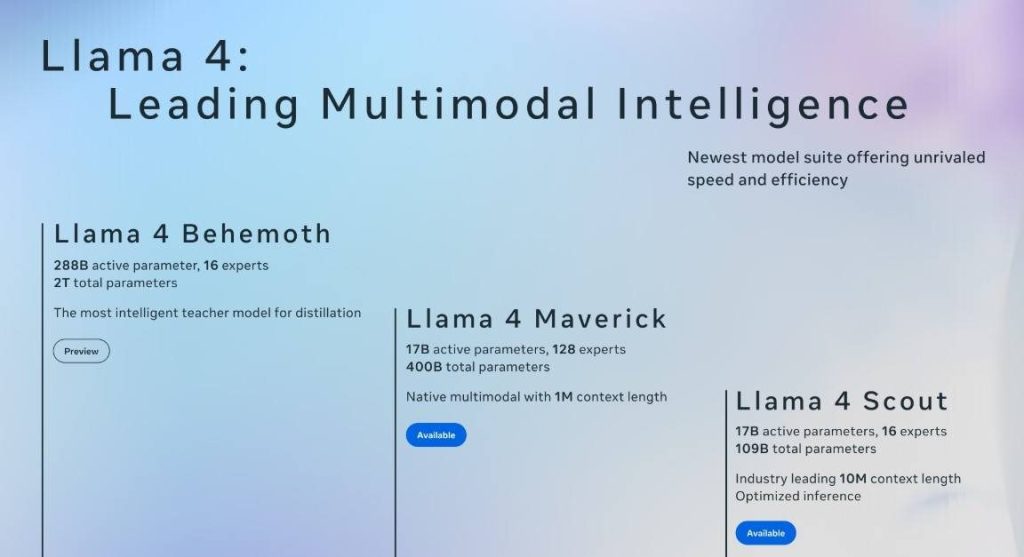
Llama 4 has officially launched. Meta’s latest iteration of its Llama series introduces three exciting new models: Scout, Maverick, and Behemoth, boasting capabilities that promise to enhance various applications across industries. With a staggering total of 2 trillion parameters in its Behemoth model alone, Llama 4 represents a significant leap forward in AI technology. Here’s a closer look at what makes Llama 4 stand out.
Llama 4 Overview
What is Llama 4?
Llama 4 is Meta’s newest collection of AI models designed for multimodal intelligence—meaning they can understand and generate text, images, and potentially videos. This set includes three distinct models: Scout, Maverick, and the heavy-duty Behemoth. Each model is crafted to serve different needs while utilizing a highly efficient architecture known as “mixture-of-experts” (MoE). This innovative approach allows only relevant parts of the model to be activated depending on the task at hand, optimizing performance while conserving resources.
The introduction of Llama 4 comes at a crucial time when competition in the AI landscape has intensified. As other players like OpenAI and DeepSeek gain traction with their advanced models, Meta aims to solidify its position by providing powerful open-source solutions tailored for both developers and businesses alike.
Key Features of Llama 4
Among the standout features of Llama 4, one of the most notable is its context window length—Scout boasts an impressive capacity for handling up to 10 million tokens, while Maverick manages around 1 million tokens. To put that into perspective, this means these models can interpret vast amounts of information in single interactions—an asset for data-heavy fields such as engineering or scientific research.
Additionally, all three models are equipped with state-of-the-art reasoning capabilities refined through extensive training techniques that enhance problem-solving skills across various domains like mathematics and coding. The MoE architecture also contributes significantly to their efficiency; instead of running entire models for every task, only necessary components are engaged based on user input.
Meet the New Models
Scout: The Versatile Performer
Llama 4 Scout emerges as one of the most compact yet capable offerings within this new lineup. Designed to fit comfortably onto a single Nvidia H100 GPU without sacrificing performance quality, it excels in tasks requiring swift responses with high accuracy. With a context window that accommodates up to 10 million tokens, Scout allows users to interact with large datasets seamlessly.
It competes favorably against other prominent models such as Mistral 3.1 and Gemini 2.0 Flash-Lite across various benchmarks—a testament to its versatility and robust design tailored for efficient deployment on devices ranging from individual workstations to larger server setups.
Here’s how Scout stacks up against some competitors:
| Model | Context Length | Performance |
|---|---|---|
| Llama 4 Scout | Up to 10M | Beats Mistral & Gemini |
| Mistral 3.1 | Standard | Comparable |
| Gemini 2.0 Flash-Lite | Standard | Competitive |
Maverick: Pushing Boundaries
Next up is Llama 4 Maverick—a model that takes things further by pushing boundaries both in size and capability. With approximately 400 billion active parameters, it serves as an advanced tool tailor-made for complex multimodal tasks such as detailed content generation or interactive question-answering sessions.
Maverick’s architecture enables it not just to compete but often outperform leading proprietary models like OpenAI‘s GPT-4o on numerous benchmarks related to reasoning tasks while being cost-effective—estimated operational costs range between $0.19–$0.49 per million tokens, making it an attractive choice compared to pricier alternatives.
Furthermore, it’s worth noting that Maverick’s capacity extends beyond mere numerical prowess; its integration into platforms like WhatsApp and Instagram Direct showcases its accessibility for everyday users who may not have technical expertise but still want robust AI functionality at their fingertips.
Behemoth: The Heavyweight Champion
Rounding out this remarkable trio is Llama 4 Behemoth—the heavyweight champion boasting an astonishing total parameter count reaching 2 trillion! Although still undergoing training at present, early indications suggest it will significantly outperform established competitors like GPT-4.5 across several STEM benchmarks once fully operational.
With its unprecedented scale comes immense potential; Behemoth aims not merely at gradual advancements but rather sets sights on redefining what large language models can accomplish when equipped with cutting-edge reasoning capabilities tailored through iterative learning processes unique to Meta’s development philosophy.
Here’s a snapshot comparison focusing on parameters:
| Model | Total Parameters | Current Status |
|---|---|---|
| Llama 4 Behemoth | Up to 2 Trillion | In Training |
| GPT-4 | Approximate ~175B | Active |
| Claude Sonnet | Approximate ~150B | Activ |
Llama 4’s Impact on AI Development
Advancements in AI Technology
The launch of Llama 4 signifies an important advancement not just for Meta but also for broader trends within artificial intelligence development worldwide. By employing new methodologies such as MoE architecture paired with enhanced reasoning techniques via tools like MetaP—engineers can optimize workflows effectively while enabling faster experimentation cycles during model training stages without incurring prohibitive costs traditionally associated with large-scale deployments.
Such innovations stand poised not only against existing players but also challenge assumptions about resource allocation required within machine learning infrastructure—a shift likely motivating further exploration among competing entities seeking similar efficiencies moving forward into future releases or iterations.
Applications Across Industries
The applications stemming from these advancements are vast across multiple sectors including healthcare diagnostics where long-context analysis could revolutionize patient records management systems or educational technologies harnessing adaptive learning mechanisms powered by real-time feedback derived from student interactions processed through these sophisticated architectures!
From automating customer service inquiries via intelligent chatbots built upon these frameworks interfacing directly through platforms familiarized by everyday users (think Messenger), all signs point towards continued integration opportunities expanding far beyond traditional limits previously observed within generative conversational agents powered solely by linear response paradigms!
In summary, we see how each new aspect introduced alongside Llama 4 encapsulates opportunity-driven engagement strategies necessary today amidst accelerating competition characterized prominently throughout this rapidly evolving tech landscape!
Frequently asked questions on Llama 4
What is Llama 4 and what models does it include?
Llama 4 is Meta’s latest AI model collection designed for multimodal intelligence, featuring three main models: Scout, Maverick, and Behemoth. Each model serves distinct purposes while utilizing an efficient architecture known as “mixture-of-experts” (MoE).
How many parameters does the Behemoth model have in Llama 4?
The Behemoth model in Llama 4 boasts an astonishing total of 2 trillion parameters, making it one of the most powerful AI models currently in development.
What are the key features of the Scout model in Llama 4?
The Scout model can handle up to 10 million tokens, allowing for seamless interaction with large datasets. It’s designed to be compact yet high-performing, fitting comfortably onto a single Nvidia H100 GPU.
How does Maverick compare to other AI models?
Maverick has approximately 400 billion active parameters, excelling in complex multimodal tasks. It competes effectively against leading proprietary models like OpenAI’s GPT-4o while maintaining cost-effective operational expenses.
How does Llama 4 utilize mixture-of-experts architecture?
Llama 4‘s use of mixture-of-experts (MoE) architecture allows only relevant parts of the model to be activated based on specific tasks, optimizing performance while conserving resources.