
Touted as the company’s largest model to date, GPT-4.5 is designed to enhance various applications, from coding tasks to more nuanced human interactions. While it reportedly outshines its predecessor, GPT-4o, it’s essential to delve into the specifics of its capabilities and limitations. Let’s talk about OpenAI’s latest release, GPT-4.5 and its performance claims.
Key Features of GPT-4.5
GPT-4.5 brings several exciting features that set it apart from previous models like GPT-4o. One of the most notable enhancements is its emotional intelligence—OpenAI claims that this model can engage in more human-like conversations with a warmer tone and better understanding of context. This improvement is not just about conversation; it extends to recognizing patterns and drawing connections within complex datasets.
Additionally, OpenAI emphasizes that GPT-4.5 has been trained on a significantly larger dataset than earlier iterations, allowing it to possess “deeper world knowledge.” The model also shows improved performance in reducing hallucinations—instances where AI generates incorrect or nonsensical information—which is crucial for maintaining credibility and accuracy in responses.
Moreover, features such as file uploads and advanced image processing capabilities have been integrated into this version, making it versatile for various applications beyond mere text generation. As noted by OpenAI, these advancements aim to create a more robust foundation for future reasoning models.
Comparison with GPT-4
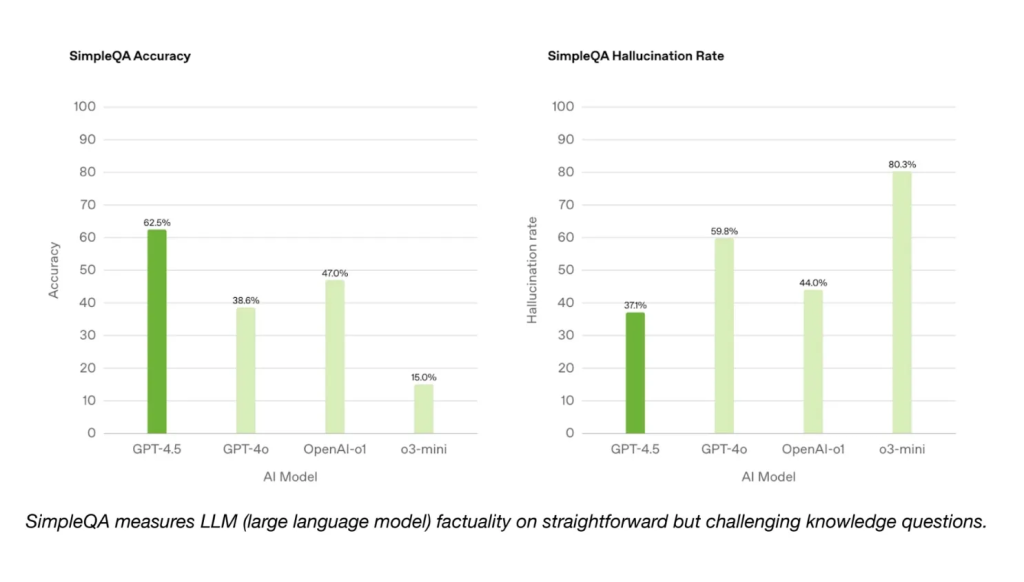
When comparing GPT-4.5 performance with that of GPT-4o, the improvements are evident but perhaps less dramatic than some might expect given the hype surrounding its launch. For instance, on benchmarks like SimpleQA Accuracy and SWE-Bench Verified, GPT-4.5 scored 62.5% and 38%, respectively—both marked increases over GPT-4o’s scores but still falling short when compared to leading models such as Anthropic’s Claude 3.7 Sonnet.
| Benchmark | GPT-4o Score | GPT-4.5 Score | Deep Research Score |
|---|---|---|---|
| SimpleQA Accuracy | 38.2% | 62.5% | Not Reported |
| SWE-Bench Verified | 36%-37% | 38% | ~68% |
Performance Metrics and Results
In coding benchmarks like SWE-Bench Verified and SWE-Lancer Diamond tests developed by OpenAI’s Preparedness team, results show that while GPT-4.5 performs admirably on certain tasks—matching or slightly outperforming both GPT-4o and o3-mini—it does not reach the heights set by OpenAI’s own deep research models or competitors’ offerings.
For example:
- In SWE-Lancer Diamond benchmark tests focused on developing software features:
- GPT-4 o: Achieved around 20%
- GPT–45: Slightly improved upon this score.
- On SWE-Bench Verified:
- Both versions showed modest improvements over their predecessors but failed to surpass deep research scores significantly.
These metrics suggest that while there are gains in specific areas related to coding tasks—like debugging or feature development—the overall leap forward may not be as revolutionary as anticipated.
Source: OpenAI
Real-World Coding Applications
The real-world implications of these benchmarks are fascinating yet complex because developers often seek practical applications rather than theoretical prowess alone. For instance:
- Developers using tools powered by OpenAI might find that while they can rely on faster code generation with fewer errors due to reduced hallucination rates in responses, they still need supplementary checks when working on complex projects.
- Tasks such as bug fixing or feature development see notable improvements thanks to enhanced contextual understanding within code snippets provided by users.
This blend of capability enhancement alongside existing limitations forms an intriguing narrative about how businesses will adopt these tools moving forward—leveraging them for efficiency while remaining aware of their boundaries.
Where GPT-4.5 Falls Short Against Deep Research
Despite its advancements over prior iterations like GPT–40 , there are critical areas where GPT–45 performance pales compared to cutting-edge AI reasoning models like those developed under OpenAI’s deep research initiative or similar high-caliber competitors from other firms.
Limitations in Advanced Tasks
One glaring shortcoming lies in handling complex academic challenges or intricate problem-solving scenarios requiring advanced reasoning skills—a domain where leading alternatives excel dramatically over all non-reasoning counterparts including both versions offered by OpenAI itself (i.e., o3-mini).
For example:
- In difficult academic benchmarks such as AIME (American Invitational Mathematics Examination) & GPQA (Generalized Problem Question Answering), results indicate substantial gaps between what was achieved through traditional scaling methods versus newer approaches being experimented with across industries.
- The inability of GPT–45 to consistently match outputs produced via dedicated reasoning frameworks raises questions about long-term viability concerning competitive positioning within rapidly evolving landscapes dominated by innovative startups focusing solely on enhancing logic-driven functionalities instead!
Insights from Industry Experts
Industry experts have voiced concerns regarding whether scaling efforts alone will suffice moving forward without integrating deeper cognitive frameworks into training methodologies employed during pre-training phases; many believe we’ve reached a plateau where merely increasing data volume won’t yield proportional returns anymore!
Ilya Sutskever himself remarked back in December about achieving “peak data,” implying fundamental shifts must occur if we aim towards sustained advancements beyond current limits observed today! This sentiment resonates among stakeholders across sectors who recognize urgency surrounding exploration opportunities presented through hybridization strategies combining strengths inherent within both non-reasoning models alongside emerging reasoning architectures alike!
Frequently asked questions on GPT-4.5 performance
What are the key features of GPT-4.5 that enhance its performance?
GPT-4.5 boasts several exciting features, including improved emotional intelligence for more human-like conversations, a larger training dataset providing deeper world knowledge, and enhanced capabilities in reducing hallucinations. These advancements aim to create a more robust foundation for various applications beyond simple text generation.
How does GPT-4.5’s performance compare to GPT-4o?
The GPT-4.5 performance shows marked improvements over GPT-4o in benchmarks like SimpleQA Accuracy and SWE-Bench Verified, with scores of 62.5% and 38%, respectively. While these figures indicate progress, they still fall short compared to leading models from competitors.
In which coding benchmarks does GPT-4.5 excel?
In coding benchmarks such as SWE-Lancer Diamond and SWE-Bench Verified, GPT-4.5 performs admirably by matching or slightly outperforming both GPT-4o and o3-mini. However, it does not reach the heights set by OpenAI’s deep research models or those from competitors.
Where does GPT-4.5 fall short against Deep Research models?
Despite its advancements, GPT–45 performance struggles with complex academic challenges requiring advanced reasoning skills, where leading alternatives significantly outperform it. This gap raises questions about its competitive positioning in rapidly evolving AI landscapes.
What improvements can we expect from future iterations of OpenAI’s models?
The evolution of OpenAI’s models is likely to focus on integrating deeper cognitive frameworks into training methodologies rather than just increasing data volume alone.
How do industry experts view the current state of AI model development?
Experts express concerns that merely scaling efforts may not suffice for future advancements; they advocate for innovative hybridization strategies that combine non-reasoning models with emerging reasoning architectures.
Is there a significant difference between coding tasks performed by GPT-4o and GPT-4.5?
The differences are notable but perhaps less dramatic than expected; while both show improvements over their predecessors in coding tasks, neither surpasses deep research scores significantly.
Will businesses adopt tools powered by GPT-4.5 despite its limitations?
Yes! Businesses are likely to leverage the efficiency gains offered by tools powered by OpenAI, even while remaining aware of their boundaries when tackling complex projects.